This article is more than 1 year old
Google boffins tease custom AI math-chip TPU2 stats: 45 TFLOPS, 16GB HBM, benchmarks
Missing key info, take with a pinch of salt, YMMV
If you've been curious about the potential performance of Google's TPU2 – its second-generation custom neural-network math acceleration chip – well, here's an early Christmas present.
Google engineering veteran Jeff Dean and fellow Googler Chris Ying unveiled a few more details [PDF] about the silicon at the Neural Information Processing Systems (er, NIPS) conference in Los Angeles, California, last week.
The internet advertising giant has been tight-lipped about its TPU2, so far declining to publish any documentation or papers detailing the chipset's architecture and specs. All we know is that the silicon is designed for accelerating calculations required by AI software, taking the workload off general-purpose processors and GPUs, and therefore loosening the grip of chip giants (cough, cough, Intel, splutter, cough, Nvidia) from Google.
During Dean’s talk in a machine-learning systems workshop at the conference, he revealed that each second-generation Tensor Processing Unit v2 device contains four chips, each containing:
- Two cores, each with a 128x128 mixed multiply unit (MXU) and 8GB of high-bandwidth memory, adding up to 64GB of HBM for one four-chip device.
- 600 GB/s memory bandwidth.
- 32-bit floating-point precision math units for scalars and vectors, and 32-bit floating-point-precision matrix multiplication units with reduced precision for multipliers.
- Some 45 TFLOPS of max performance, adding up to 180 TFLOPS for one four-chip device.

A single TPU2 device with four processor chips ... The red box shows highlights one chip. Image credits: Google
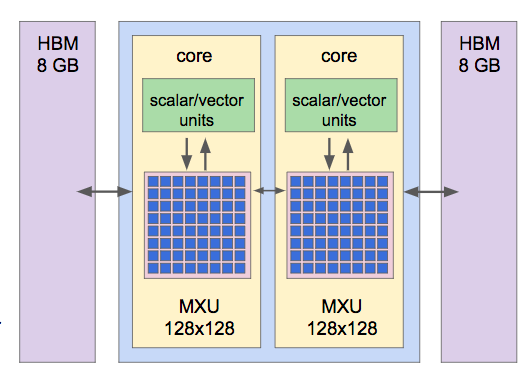
Each chip contains two cores with 8GB HBM each
Unlike its predecessor, the TPU2 ASIC can handle inference as well as training workloads. It was designed so that 64 TPU2 devices can be connected to create a pod capable of performing 11.5 PFLOPS, maximum, using 4TB of high bandwidth memory.
Ying called it a supercomputer for machine learning capable of providing the massive compute power needed to shorten training times. It can take days and even weeks to feed large datasets through neural network models during the training process, using off-the-shelf x86 and GPU hardware. Researchers often repeat the process, running through the training dataset several times or epochs, tuning the weights and parameters to get the best performance for their model. Thus, Google came up with its own dedicated TPU gear to reduce that development time – down to mere hours.
There has been some initial success with the TPU2s. Google already uses it to power WaveNet, an AI system that generates a human-like voice for its Google Home digital assistants. The TPU2s are programmed via TensorFlow, and you can request cloud access to the hardware via this signup page. You can't buy this gear from a store: Google uses the silicon internally, and grants some access to it via its cloud.
Ying showed the training times for ResNet-50 v2, an image-recognition model, using ImageNet, a popular database containing millions of labeled images in different categories, using an increasing number of TPU2s. It took 23 hours and 22 minutes on a single TPU2 to train ResNet-50 v2 using a batch size of 256 photos for 90 epochs – 90 runs through the dataset – to an accuracy of 76.6 per cent. But only 45 minutes on 32 TPU2s – half a pod – for 90 epochs and a batch size of 8,192 to an accuracy of 76.1 per cent.
There is a big difference between going to get a cup of coffee versus going to sleep for a couple of nights whilst waiting for your models to train, Dean said. Quick turnaround times for training increases productivity, allowing researchers to experiment with new types of research like its internal AutoML project.
Researchers on the AutoML team use machines to automate the AI design process to find novel neural-network architectures. It involves searching through different building blocks and trying out new strategies before settling on architectures that are often much larger and complex than ones handcrafted by human developers.
But some details of the TPU2 remain unclear. When faced with questions from the audience at a workshop talk by Ying, he said he could not discuss some aspects of the chip including the precision of the matrix multiplications, and how much power it consumed. El Reg has heard the TPU2s – being far more advanced than the first-generation TPU, which only supported a handful of instructions – are not easy to program, prompting Google bosses to hunt down and reassign engineers capable of wrangling TensorFlow and parallelized matrix-heavy code onto TPU2-powered projects.
At the moment, TPU2s are only available for Google eggheads and engineers, but there are plans to make 1,000 of them available for free to “top researchers committed to open machine learning research.” ®
